
Dit artikel is ouder dan vier jaar. De inhoud kan verouderd zijn, vooral bij technische voorbeelden of verwijzingen naar tooling.
Een crawler is - zoals omschreven in de IT Glossary
van Gartner
(Gartner, Gartner IT
Glossary, 2013)
Kenmerken van een crawler
Elke crawler bestaat minimaal uit een aantal componenten zoals afgebeeld in onderstaande afbeelding. Elke component heeft een specifieke taak en eigen verantwoordelijkheden. Om een goed beeld te krijgen van een crawler en de componenten wordt per component een uitleg gegeven over de taken en verantwoordelijkheden.
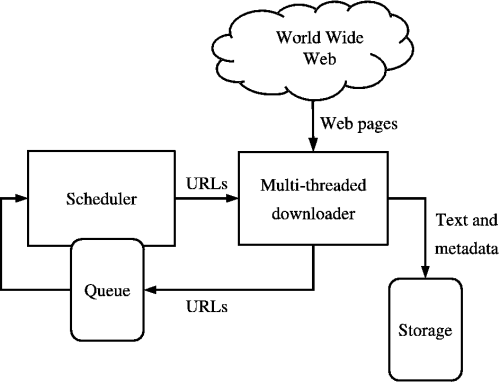
Component 1: Scheduler
De Scheduler zorgt ervoor dat de Downloader
wordt voorzien van nieuwe URL's uit de Queue. De Scheduler zal elke keer de
eerste URL uit de lijst van de Queue aan de Downloader doorgeven. De Queue is
als de crawler wordt gestart gevuld met één URL; het startpunt.
Als de Downloader multi-threaded
Component 2: Downloader
De Downloader downloadt webpagina's. URL's die
worden gevonden op deze webpagina worden onthouden.
Naast het zoeken naar URL's zal de Downloader ook zoeken naar benodigde informatie. De gevonden data zal door de Downloader worden opgeslagen in een database. In figuur 2 is dit de Storage. De storage is geen onderdeel van de crawler.
Component 3: Queue
De Queue ontvangt van de Downloader continu
nieuw gevonden URL's. De Queue zal per URL controleren of de URL al een keer
eerder is bekeken. Nog niet bekeken URL's zal de Queue onthouden in een lijst –
de Queue. Deze lijst is gevuld met URL's die door de Downloader moeten worden
doorzocht.
De Queue houdt ook een lijst bij met URL's die al gecontroleerd zijn, zodat er bepaald kan worden welke URL's niet in de queue geplaatst hoeven te worden.
Een crawler volgt dus continue de volgende stappen (Aviral, 2014);
- Selecteer en verwijder URL uit de Queue - Scheduler
- Download de webpagina achter de URL - Downloader
- De relevatie van de webpagina controleren - Downloader
- Eventueel data opslaan (geen onderdeel van de crawler)
- URL's uit de pagina toevoegen aan de Queue - Queue
Crawlmethodes
Crawlers maken gebruik van verschillende
methoden om webpagina's te crawlen. De drie meest gebruikte crawlmethoden zijn; Breadth First search, Best First Search
en Depth First Search
(M. Diligenti, 2000)
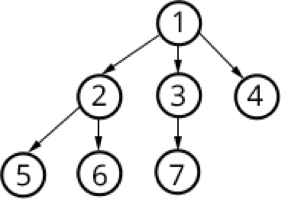 Breadth First Search
Breadth First Search
De Breadth First Search methode is de meest
standaard crawlmethode die er is. De methode gaat er van uit dat er vanuit één
link wordt begonnen met zoeken naar andere links, vervolgens worden de gevonden
links gebruikt om te zoeken naar nieuwe links. Recursief wordt op deze manier
het internet van URL naar URL doorzocht. Gevonden URL's worden in dezelfde
volgorde als ze gevonden zijn. De Breadth First Search gaat dus uit van het
FIFO principe: First In First Out
(Junghoo
Cho, 1998)
.
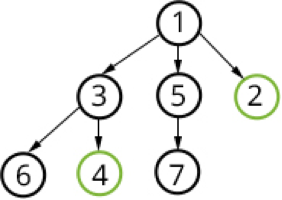
Best First Search
Bij deze methode worden de URL's in de Queue
geordend op relevantie. Er wordt dus geen FIFO principe gehanteerd. De eerste
URL in de queue is de meest relevante URL in de Queue. De relevantie wordt door
de Queue bepaald. Als er nieuwe URL's worden toegevoegd aan de Queue wordt de
relevantie opnieuw bepaald en wordt de volgorde van de Queue opnieuw ingedeeld,
dit proces heet Link Analysis.
De relevantie wordt bepaald aan de hand van een verwachting. Doorgaans wordt de
URL gecontroleerd op bepaalde elementen. Door vooraf een schatting te
doen van de relevantie van een website worden relevante websites eerder door de
Best First Search methode gecrawld.
Het voordeel van de Best First Search crawlmethode tegenover de Breadth First Search crawlmethode is dat de crawler sneller met bruikbare resultaten zal komen. Minder relevante websites zullen minder hoog in de queue staan waardoor sneller resultaten of relevante informatie door de crawler worden gevonden (Padmini Srinivasan, 2001) .
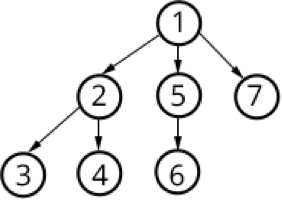
Depth First Search
Bij de Depth First Search Methode worden de gevonden
URL's toegevoegd aan de Queue. Deze methode hanteert niet het FIFO principe en ordent
de URL's ook niet op relevantie. De Queue wordt zo opgebouwd dat de crawler bij
elke nieuwe URL een niveau dieper crawlt
(Alvaro E. Monge, 1999).
Zoals te zien is in figuur 5 zal de crawler na het crawlen van de eerste URL van de eerste pagina niet de tweede URL crawlen, maar de eerst gevonden URL van de eerste pagina. Dit principe wordt herhaald tot het pad eindigt. Als het pad eindigt zal van de eerste pagina het pad tot het eind worden gevolgd van de tweede URL. Ook dit principe zal worden herhaald, als het pad achter de tweede URL is afgelopen wordt het pad achter de derde URL afgelopen. Als van de eerste pagina alle URL paden zijn doorlopen zal van de tweede pagina alle URL paden worden doorlopen.
Het voordeel van Depth First Search crawlen is dat in relatief laag aantal stappen al diep op het internet kan worden gezocht. Als er op een bepaalde diepte informatie wordt gevonden kan een crawler met de Depth First Search methode overgaan op een Best First Search methode waardoor in een diepe laag in de crawl Queue resultaten eerder gevonden worden.